高频问题
1、AOP和IOC
(1)AOP
AOP(面向切面编程):通过在运行时动态地将代码切入到类的某个特定方法、特定位置执行,实现功能的复用和解耦。AOP 的核心思想是将业务逻辑和横切关注点分离开来,通过切面(Aspect)来实现横切关注点的代码复用,是OOP(面向对象编程)的一种延续。
Spring AOP主要基于动态代理(JDK动态代理和CGLIB代理)来实现切面功能。
- JDK动态代理,是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
- CGLib动态代理,采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
(2)IOC
IOC(控制反转):控制反转实际上就是当你想要创建对象的时候不自己去创建,而是向Spring IOC容器发起请求, 告诉他我要创建哪个哪个对象了, 然后Spring IOC容器就会返回一个对象实例给你,这就是IOC控制反转,将创建对象的权利交由Spring IOC容器管理。
依赖注入是IOC控制反转的具体实现,是实现用于解决依赖性设计模式。因为对象资源的获取全部要依赖于Spring IOC容器, 组件之间的依赖关系由容器在应用系统运行期来决定,在需要的时候由Spring IOC容器动态地往组件中注入需要的实例对象,就叫依赖注入。
2、Spring AOP的实现方式
JDK动态代理,是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
CGLib动态代理,采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
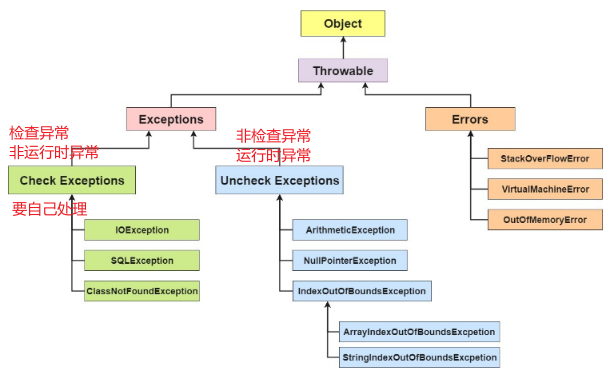
3、Java中的异常
4、线程的状态
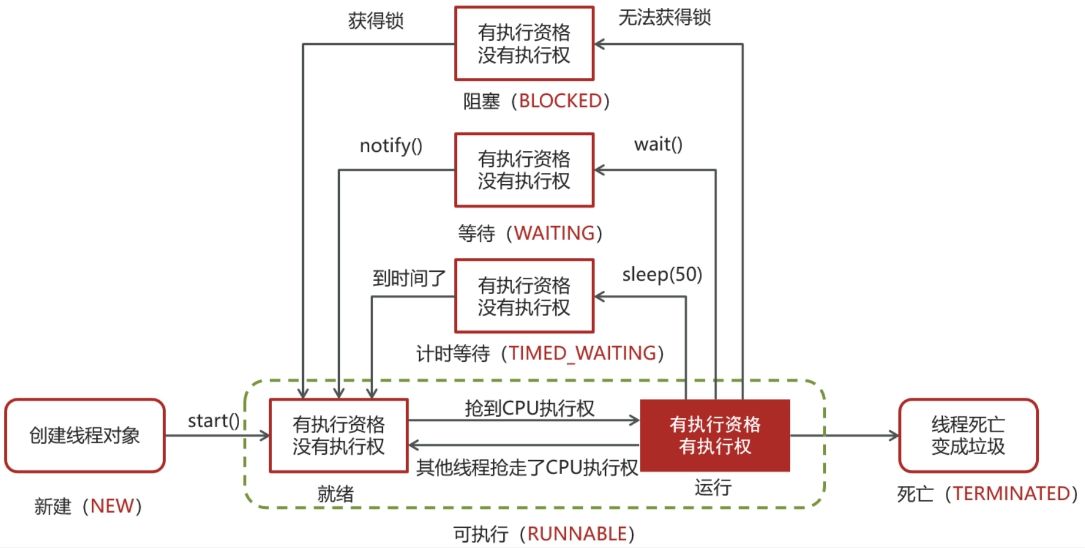
- NEW(新建):线程对象已经创建,但尚未启动。
- RUNNABLE(可运行):线程正在Java虚拟机中执行,可能正在等待CPU时间片。
- BLOCKED(被阻塞):线程被阻塞等待监视器锁,例如在synchronized块或方法内部尝试获取锁时。
- WAITING(等待):线程无限期地等待另一个线程执行特定操作,直到其他线程显式地唤醒它。
- TIMED_WAITING(计时等待):线程在等待一段有限的时间,时间到达后会自动恢复。
- TERMINATED(终止):线程执行完毕或者因异常退出,处于终止状态。
5、多线程实现方式
(1)继承Thread类
public class MyThread extends Thread{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(getName()+": Hello,World");
}
}
}
public class MyThreadDemo {
public static void main(String[] args) {
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
t1.setName("线程1");
t2.setName("线程2");
// 启动线程
t1.start();
t2.start();
}
}
(2)实现Runnable接口
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
//获取到当前线程的对象
/*Thread t = Thread.currentThread();
System.out.println(t.getName() + "HelloWorld!");*/
System.out.println(Thread.currentThread().getName() + ":HelloWorld!");
}
}
}
public class MyRunnableDemo {
public static void main(String[] args) {
//创建MyThread的对象
//表示多线程要执行的任务
MyRunnable myThread = new MyRunnable();
//创建Thread类的对象,把MyRunnable对象作为构造方法的参数
/*Thread t1 = new Thread(myThread);
Thread t2 = new Thread(myThread);
//给线程设置名字
t1.setName("线程1");
t2.setName("线程2");*/
// Thread(Runnable target, String name)方法
Thread t1 = new Thread(myThread,"线程1");
Thread t2 = new Thread(myThread,"线程2");
//开启线程
t1.start();
t2.start();
}
}
(3)实现Callable接口
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
//求1~100之间的和
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum = sum + i;
}
return sum;
}
}
public class MyCallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建MyCallable的对象(表示多线程要执行的任务)
MyCallable myCallable = new MyCallable();
//创建FutureTask的对象(作用管理多线程运行的结果)
FutureTask<Integer> ft = new FutureTask<>(myCallable);
//创建线程的对象
Thread t1 = new Thread(ft);
//启动线程
t1.start();
//获取多线程运行的结果
Integer result = ft.get();
System.out.println(result);
}
}
(4)使用线程池
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("Thread is running");
}
});
}
executorService.shutdown(); // 关闭线程池
}
}
6、Runnable和Callable有什么区别
- Runnable 接口run方法没有返回值;Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
- Callalbe接口支持返回执行结果,需要调用FutureTask.get()得到,此方法会阻塞主进程的继续往下执行,如果不调用不会阻塞。
- Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛,但可以使用try catch。
7、如何保证线程安全
Java中保证线程安全主要有以下几种方法:
同步方法(synchronized):使用synchronized关键字修饰方法或者代码块,保证一次只允许一个线程执行同步方法或代码块。
信号量(Semaphore):使用java.util.concurrent.Semaphore类控制同时访问特定资源的线程数量。
互斥锁(ReentrantLock):使用java.util.concurrent.locks.ReentrantLock类替代synchronized实现排它锁。
无锁编程:使用原子类如AtomicInteger来替代非线程安全类,这样可以避免同步开销。
线程本地存储(ThreadLocal):使用ThreadLocal为每个线程提供独立的实例副本,避免线程安全问题。
同步集合类:如ConcurrentHashMap使用synchronization和CAS操作保证线程安全。
线程隔离:每个线程操作各自的数据副本,避免对共享数据的访问。
可见性:使用volatile或synchronized关键字保证指令重排导致的可见性问题。
线程池:使用ThreadPoolExecutor等线程池控制最大线程数量,避免过多线程同时访问资源。
正常结束线程:正确关闭,销毁或中断线程以避免对共享状态的不正确访问。、
8、synchronized和ReentrantLock区别
简单场景下使用synchronized;复杂场景需要更多高级功能可以使用ReentrantLock。主要区别如下:
- 获得锁和释放锁的操作不同:
synchronized是JVM实现的,获得和释放锁是自动的。
ReentrantLock需要手动调用
lock()和unlock()方法获得和释放锁。
- 等待锁和唤醒机制不同:
synchronized使用内置锁机制,等待锁变成非阻塞模式。
ReentrantLock 使用Condition实现等待和唤醒,可以选择使用阻塞或者非阻塞方式等待锁。
- 性能不同:
在简单情况下,synchronized效率较高。
在复杂场景下,如需要非阻塞锁、加锁中断等,ReentrantLock性能更好。
- 特性不同:
synchronized不支持锁重入计数,是非公平锁。
ReentrantLock 既可以是公平锁也可以是非公平锁,默认情况下 ReentrantLock 为非公平锁,且支持锁重入。
- 用法不同:
synchronized用于方法和代码块。
ReentrantLock除锁功能外,还提供其他高级工具类CountDownLatch等。
9、线程池状态
在Java中,线程池的状态通常由ThreadPoolExecutor类的几个状态常量表示,主要包括以下几种状态:
- RUNNING:线程池处于运行状态,接受新任务并处理排队的任务。
- SHUTDOWN:线程池处于关闭状态,不再接受新任务,但会继续处理已经提交的任务。
- STOP:线程池处于停止状态,不再接受新任务,不处理已经提交的任务,并会中断正在执行的任务。
- TIDYING:所有任务都已经终止,工作线程数量为0,线程转换为TIDYING状态将运行terminated()钩子方法。
- TERMINATED:线程池处于终止状态,terminated()方法完成后就会到达这个状态。
这些状态常量可以通过ThreadPoolExecutor类的get方法来获取线程池当前的状态。
8、线程池的参数
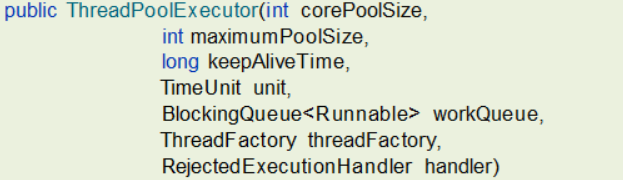
- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目 = (核心线程+救急线程的最大数目),救急线程没显示在这7个参数中
- keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放。临时线程也叫救急线程、非核心线程。
- unit 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务。可视为阻塞队列。
- threadFactory 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
9、线程池执行原理
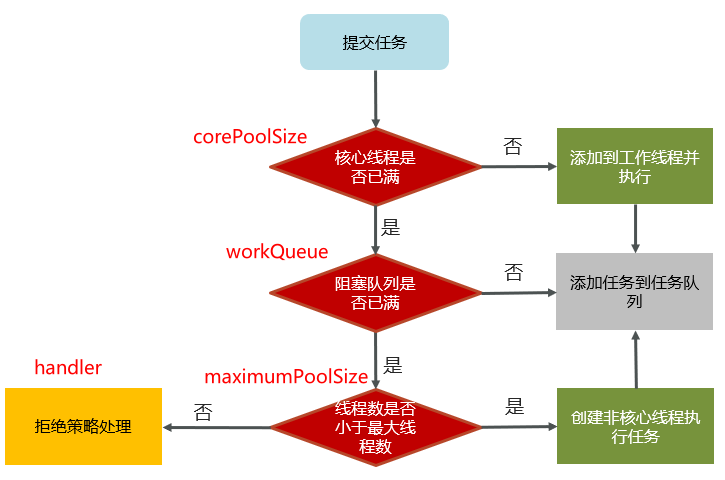
(1)任务在提交的时候,首先判断核心线程数是否已满,如果没有满则直接添加到工作线程执行 (2)如果核心线程数满了,则判断阻塞队列是否已满,如果没有满,当前任务存入阻塞队列 (3)如果阻塞队列也满了,则判断线程数是否小于最大线程数,如果满足条件,则使用临时线程执行任务 (4)如果核心或临时线程(非核心线程)执行完成任务后会检查阻塞队列中是否有需要执行的线程,如果有,则使用非核心线程执行任务 (5)如果所有线程都在忙着(核心线程+临时线程),则走拒绝策略。
拒绝策略(如: new ThreadPoolExecutor.CallerRunsPolicy()):
- AbortPolicy:直接抛出异常,默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:直接丢弃任务;
10、线程池的种类
在 Java 中,java.util.concurrent 包提供了几种常用的线程池实现,每种线程池都有其特定的用途和行为。以下是几种主要的线程池类型:
(1)FixedThreadPool
FixedThreadPool 是一个具有固定数量线程的线程池。线程池中的线程数量在创建时指定,并且不会改变。适用于需要限制并发线程数量的场景。
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);
(2)CachedThreadPool
CachedThreadPool是一种适用于执行大量短时间任务的线程池实现,它可以根据需求动态创建和回收线程,提高资源利用率。
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
(3)ScheduledThreadPool
ScheduledThreadPool 是一个可以在给定延迟后运行任务,或者定期执行任务的线程池。适用于需要定时或周期性执行任务的场景。
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(int corePoolSize);
(4)SingleThreadExecutor
SingleThreadExecutor 是一个只有一个线程的线程池,所有任务将被顺序执行。适用于需要保证任务按顺序执行的场景。
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
(5)WorkStealingPool
WorkStealingPool 是一个基于工作窃取算法的线程池,适用于并行计算任务。它会创建足够多的线程来充分利用处理器的并行能力。
ExecutorService workStealingPool = Executors.newWorkStealingPool();
(6)自定义 ThreadPoolExecutor
除了使用 Executors 工厂方法创建线程池,还可以直接使用 ThreadPoolExecutor 类来创建自定义线程池。这样可以更精细地控制线程池的行为,例如核心线程数、最大线程数、线程空闲时间、任务队列等。
import java.util.concurrent.*;
public class ThreadPoolExecutorExample {
public static void main(String[] args) {
int corePoolSize = 5;
int maximumPoolSize = 10;
long keepAliveTime = 60L;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(100);
// 创建线程池,使用CallerRunsPolicy作为拒绝策略
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:用调用者所在的线程来执行任务
);
for (int i = 0; i < 15; i++) {
Runnable task = new Task(i);
threadPoolExecutor.execute(task);
}
// 关闭线程池
threadPoolExecutor.shutdown();
}
}
class Task implements Runnable {
private int taskId;
public Task(int id) {
this.taskId = id;
}
@Override
public void run() {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
11、线程安全的集合
Vector是一个线程安全的动态数组。它的方法是同步的,因此可以在多线程环境中安全地使用。`Hashtable是一个线程安全的哈希表。它的方法是同步的,因此可以在多线程环境中安全地使用。Collections.synchronizedList返回一个线程安全的List,它是通过对现有的List进行包装实现的。Collections.synchronizedMap返回一个线程安全的Map,它是通过对现有的Map进行包装实现的。Collections.synchronizedSet返回一个线程安全的Set,它是通过对现有的Set进行包装实现的。ConcurrentHashMap是一个高效的线程安全的哈希表实现。它允许并发读取和写入操作,性能优于Hashtable。CopyOnWriteArrayList是一个线程安全的List实现,适用于读操作远多于写操作的场景。写操作会创建一个新的底层数组,因此读操作不会被阻塞。CopyOnWriteArraySet是一个线程安全的Set实现,适用于读操作远多于写操作的场景。它基于CopyOnWriteArrayList实现。ConcurrentSkipListMap是一个线程安全的NavigableMap实现,基于跳表数据结构。它支持高效的并发访问。ConcurrentSkipListSet是一个线程安全的NavigableSet实现,基于跳表数据结构。它支持高效的并发访问。
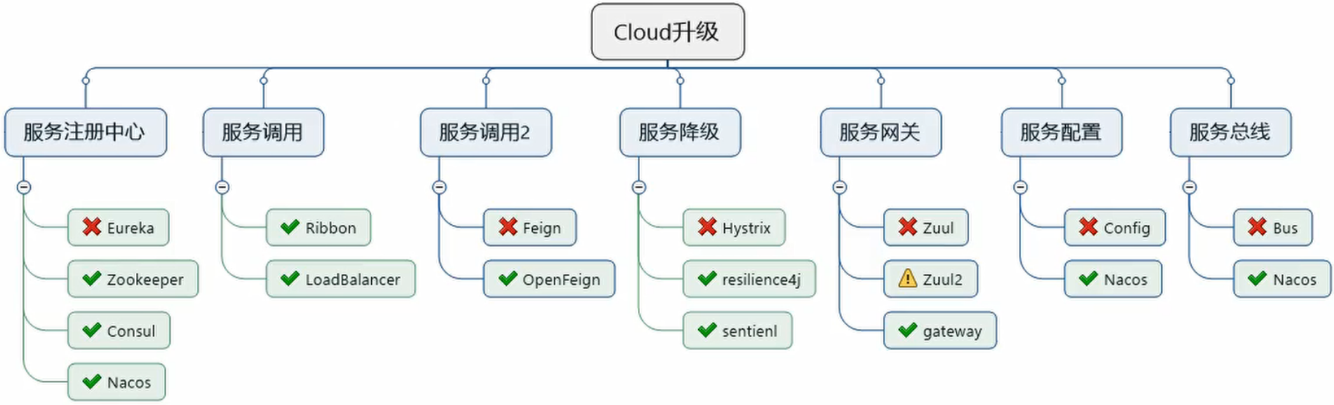
12、SpringCloud常用组件
13、事务的基本特性
事务是一个逻辑上的一组操作,这些操作要么全部成功,要么全部失败。事务具有四个基本特性,通常称为 ACID 特性:
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成。
- 一致性(Consistency):事务完成后,数据库必须处于一致的状态。
- 隔离性(Isolation):一个事务的执行不应影响其他事务的执行。
- 持久性(Durability):事务完成后,其结果应永久保存在数据库中。
14、Spring事务管理方式
- 声明式事务管理:通过注解或 XML 配置来管理事务,简洁易用,适合大多数场景。
- 编程式事务管理:通过编写代码显式地管理事务,提供更大的灵活性,但通常不如声明式事务管理简洁和易维护。
15、事务管理注解@Transactional
@Transactional可以作用在类上,代表这个类的所有公共非静态方法都将启用事务; 可以通过@Transactional的propagation属性,指定事务的传播行为; 可以通过@Transactional的isolation属性,指定事务的隔离级别; 可以通过@Transactional的rollbackFor属性,指定发生哪些异常时回滚。
16、Spring中@Transactional注解事务失效的的原因
第一个,如果方法上异常捕获处理,自己处理了异常,没有抛出,就会导致事务失效,所以一般处理了异常以后,别忘了抛出去就行了。
第二个,如果方法抛出检查异常,如果报错也会导致事务失效,最后在spring事务的注解上,就是@Transactional上配置rollbackFor属性为Exception,这样别管是什么异常,都会回滚事务。
第三,我之前还遇到过一个,如果方法上不是public修饰的,也会导致事务失效。
17、Spring的事务传播行为
在 Spring 中可以通过 @Transactional 注解的 isolation 属性设置隔离级别。在 Spring 中可以通过 @Transactional 注解的 propagation 属性设置传播行为。
Spring 提供了多种事务传播行为,用于定义事务方法如何与现有事务交互:
- PROPAGATION_REQUIRED:如果当前没有事务,则创建一个新事务;如果已经存在一个事务,则加入该事务。这是默认的传播行为。
- PROPAGATION_REQUIRES_NEW:总是创建一个新事务。如果当前存在事务,则将当前事务挂起。
- PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- PROPAGATION_NOT_SUPPORTED:总是以非事务方式执行,如果当前存在事务,则将当前事务挂起。
- PROPAGATION_NEVER:总是以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务中执行;如果当前没有事务,则创建一个新事务。
使用举例:
@Service
public class MyService {
@Transactional(propagation = Propagation.REQUIRED)
public void myMethod() {
// 执行需要事务管理的操作
}
}
18、事务隔离级别
MySQL事务隔离级别和Spring事务隔离级别都是这个。
读未提交(Read Uncommitted):最低的隔离级别,可能会出现脏读,几乎不提供任何数据保护。
读已提交(Read Committed):避免脏读,但可能会出现不可重复读,适用于需要避免脏读的场景。
可重复读(Repeatable Read):避免脏读和不可重复读,但可能会出现幻读,MySQL 默认的隔离级别。
可串行化(Serializable):最高的隔离级别,完全避免脏读、不可重复读和幻读,但并发性能最差。
脏读:指一个事务读取了另一个事务尚未提交的数据。这种情况可能会导致数据不一致,因为读取到的数据可能会被回滚,从而使得读取到的数据变得无效。
不可重复读:指在同一个事务中,多次读取同一行数据时,结果可能不同。这通常是因为在两次读取之间,另一个事务修改了该行数据并提交了。
幻读:指在同一个事务中,多次执行相同的查询时,结果集中可能会出现新的行。这通常是因为在两次查询之间,另一个事务插入了新的行并提交了。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 可串行化 | 不可能 | 不可能 | 不可能 |
MySQL怎么实现事务隔离级别?
MySQL中事务的隔离级别是通过设置交易隔离级别参数innodb_isolation来实现的。
MySQL支持四种事务隔离级别:
READ UNCOMMITTED:最低的隔离级别,一个事务可以看到其他未提交事务的修改。
READ COMMITTED:禁止“脏读”,但是允许“不可重复读”和“幻读”。
REPEATABLE READ:禁止“脏读”和“不可重复读”,但是允许“幻读”。这是MySQL的默认隔离级别。
SERIALIZABLE:最高的隔离级别,禁止“脏读”、“不可重复读”和“幻读”。性能最低。
MySQL通过参数innodb_isolation来设置事务的隔离级别:
- innodb_isolation = READ UNCOMMITTED
- innodb_isolation = READ COMMITTED
- innodb_isolation = REPEATABLE READ
- innodb_isolation = SERIALIZABLE
配置这个参数后,重启MySQL服务,新的事务就会采用参数指定的隔离级别。也可以在单个事务中使用SET SESSION TRANSACTION ISOLATION LEVEL来临时更改当前事务的隔离级别。
-- 查看当前事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
-- 修改事务隔离级别
SET TRANSACTION ISOLATION LEVEL [READ-UNCOMMITTED | READ-COMMITTED | REPEATABLE-READ | SERIALIZABLE];
19、@AutoWired和@Resource区别
- @AutoWired:Spring的,根据类型,可结合@Quelifier根据名称,会抛出异常,可用于构造器、属性、setter方法和配置方法上。
- @Resource:JavaEE的,根据名称,找不到名称会根据类型,不会抛出异常,用于属性和setter方法上。
20、Spring Boot自动配置原理
在Spring Boot项目中的引导类上有一个注解@SpringBootApplication,这个注解是对三个注解进行了封装,分别是:
- @SpringBootConfiguration
- @EnableAutoConfiguration
- @ComponentScan
其中**@EnableAutoConfiguration**是实现自动化配置的核心注解。
该注解通过**@Import注解导入对应的配置选择器。关键的是内部就是读取了该项目和该项目引用的Jar包的classpath路径下META-INF/spring.factories**文件中的所配置的类的全类名。
在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。
一般条件判断会有像**@ConditionalOnClass**这样的注解,判断是否有对应的class文件(比如从pom中导入了依赖就会有相关的class文件),如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。
21、Spring Boot启动流程
(1)Spring Boot 应用程序通常从一个包含 main 方法的启动类开始。这个类通常使用 @SpringBootApplication 注解。
(2)SpringApplication.run 方法是启动 Spring Boot 应用程序的入口。它负责引导整个应用程序的启动过程。
(3)SpringApplication 构造函数会初始化应用程序的基本配置。
(4)SpringApplication.run 方法会执行以下主要步骤:
- 环境:
prepareEnvironment方法会创建并配置Environment对象,包括加载配置文件和设置系统属性。 - 创建实例:
createApplicationContext方法会根据应用类型(如Servlet、Reactive或None)创建相应的ApplicationContext实例。 - 加载:
prepareContext方法会准备应用上下文,包括设置环境、加载资源、注册监听器和初始化ApplicationContextInitializer。 - Bean初始化:
refreshContext方法会刷新应用上下文,触发所有的Bean初始化和ApplicationContext事件。 - 执行Bean:在应用上下文刷新完成后,Spring Boot 会执行所有实现了
CommandLineRunner和ApplicationRunner接口的Bean。
(5)应用上下文刷新完成后,Spring Boot 应用程序启动完成,开始处理请求或执行任务。
22、Spring中bean的生命周期
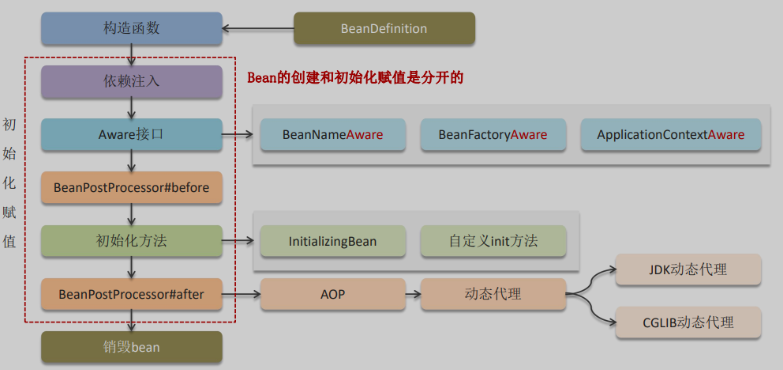
首先会通过一个非常重要的类,叫做BeanDefinition获取bean的定义信息,这里面就封装了bean的所有信息,比如,类的全路径,是否是延迟加载,是否是单例等等这些信息
在创建bean的时候,第一步是调用构造函数实例化bean
第二步是bean的依赖注入,比如一些set方法注入,像平时开发用的@Autowire都是这一步完成
第三步是处理Aware接口,如果某一个bean实现了Aware接口就会重写方法执行
第四步是bean的前置处理器BeanPostProcessor#postProcessBeforeInitialization,允许开发者对 Bean 实例进行操作或定制
第五步是初始化方法,比如实现了接口InitializingBean或者自定义了方法init-method标签或@PostContruct
第六步是执行了bean的后置处理器BeanPostProcessor#postProcessAfterInitialization,主要是对bean进行增强,有可能在这里产生代理对象
最后一步是销毁bean。
23、Spring中bean的作用域
- 单例作用域(Singleton):默认作用域,全局唯一实例。
- 原型作用域(Prototype):每次请求创建新实例。
- 请求作用域(Request):每个 HTTP 请求创建新实例,仅适用于 Web 应用。
- 会话作用域(Session):每个 HTTP 会话创建新实例,仅适用于 Web 应用。
- 全局会话作用域(Global Session):每个全局 HTTP 会话创建新实例,主要用于 Portlet 应用。
- 应用作用域(Application):与 ServletContext 生命周期相同,全局唯一实例,仅适用于 Web 应用。
- 自定义作用域:开发者可以定义自定义作用域,以满足特定需求。
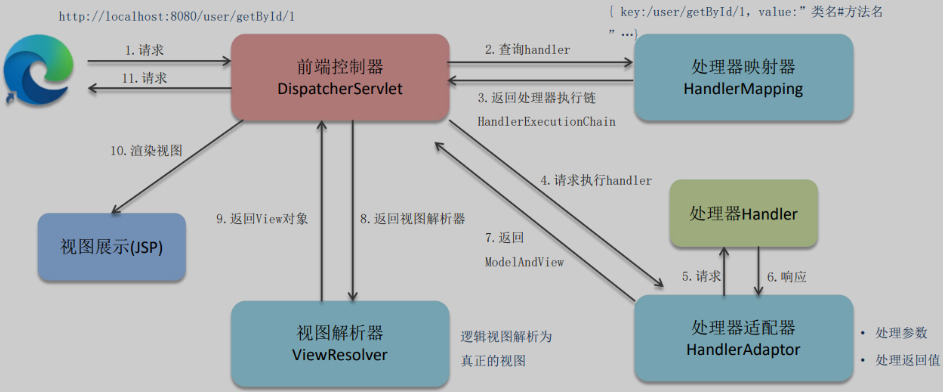
24、SpringMVC的执行流程
前后端不分离(JSP)
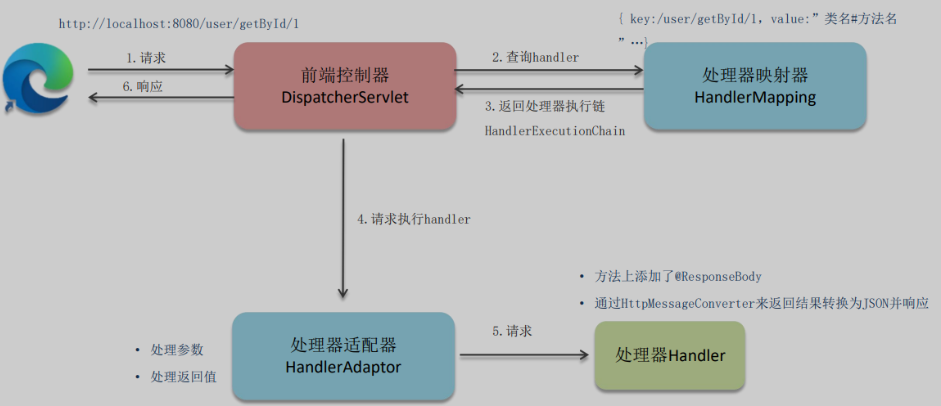
前后端分离(接口开发,异步请求)
25、Bean的注入方式
- 构造函数注入:适用于必须依赖,确保对象在创建时就已具备所有必要的依赖,推荐使用。
- Setter方法注入:适用于可选依赖或允许依赖在对象创建后进行变更的场景。
- 字段注入:简单直接,但不利于代码的可读性和单元测试,不推荐使用。
- 接口注入:用于特殊场景,例如需要动态注入多个实现类的情况下。
26、ArrayList和LinkedList区别
ArrayList:
- 基于动态数组实现。元素在内存中是连续存储的。
- 当数组容量不足时,会创建一个更大的数组并将旧数组的元素复制到新数组中。
- 由于基于数组,提供随机访问功能,因此访问元素的时间复杂度为 O(1)。
- 在中间插入或删除元素需要移动后续元素,因此时间复杂度为 (O(n))。在末尾添加元素是 (O(1))(平均情况)。
- 由于存储的是连续的数组,可能会预留一些空间以减少扩容的次数,因此可能会有浪费的空间。
- 适合频繁读取数据的场景,因为随机访问速度快。不适合频繁在中间插入和删除元素的场景。
LinkedList:
- 基于双向链表实现。元素在内存中不是连续存储的,每个元素包含一个指向前一个和下一个元素的指针。
- 由于基于链表,随机访问元素需要遍历链表,时间复杂度为 O(n)。
- 在中间插入或删除元素不需要移动其他元素,只需改变指针,时间复杂度为 (O(1))(找到插入点的时间复杂度是 (O(n)),但如果已有引用则为 (O(1)))。
- 每个元素除了存储数据外,还需要存储两个指针(前一个和后一个元素的引用),所以在内存上开销较大。
- 适合频繁在中间插入和删除元素的场景。不适合频繁随机访问的场景,因为访问速度慢。
27、ArrayList扩容机制
- 底层数据结构:ArrayList底层是用动态的数组实现的
- 初始容量:ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- 扩容逻辑:ArrayList在进行扩容的时候是原来容量的1.5倍(如果原来是10,添加第11个元素后扩容为15),每次扩容都需要拷贝数组。
- 添加逻辑:
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
- 返回添加成功布尔值。